My Journey as a Machine Learning Engineer

Introduction
One of the questions I get as a Machine Learning Engineer is whether I am required to read research papers and be aware of the latest algorithms and models. The answer is no.
Don’t get me wrong, it benefits from knowing the various models (e.g., ensemble) and techniques (e.g., supervised/unsupervised). But when it comes to a production environment, the algorithm is only a part of the ML system. The system requires considerable engineering effort, including design, deployment, monitoring, and maintenance, which is where an MLE (otherwise known as MLOps engineer) comes in.
In this article, my goal is to provide clarity on the essential technical skills required to excel as a machine learning engineer (MLE), drawing upon my personal experience in the field.
Machine Learning basics
An ML project consists of various stakeholders:

While you make the pipeline production ready, you might very likely work on refining the Data scientist’s code and/or model. It benefits to have basic knowledge of common concepts like decision trees, boosting methods, and accuracy metrics, to name a few.
Ensemble models are a popular choice for production models since it combines multiple other models in the prediction process. Examples of ensemble models: xgboost, lightgbm.
If you need a refresher on popular algorithms, here’s an outstanding lecture by Cassie Kozyrkov. Watching her lectures is like binge-watching a series.
You are an engineer first.
- Interview Process:
When I was interviewing for the MLE position, my first three rounds were problem-solving rounds. The questions were based on Data structures and algorithms.
If you need options to get started:
Free: Youtube
Paid: Coding Ninjas
No matter which course you pick, there will be no substitute for practicing questions. You can choose a platform like leetcode and start practicing high-frequency questions.
- Techstack:
Here’s a typical day at work. The business team has requested a new feature and you are responsible for deploying it. You discuss with the engineering team and come up with the technical design. You open the Python IDE and start coding. Once done, you push your changes on the Git dev branch.
Now, this feature also requires some improvement to the model and the Data scientist has raised a pull request. You go through the PR and notice that the training code has a toPandas operation. This operation executed on a large volume of data (e.g. in millions) at once is a time-consuming operation and might cause memory/CPU issues.
Instead, you change the functionality to parallelize the operation across executors (Spark Documentation). You share the metrics of the new model with the Data Scientist for validation. Ready for prod. The deployment part comes later in the article.
If you lost yourself in the story above, here’s a more refined list of the tech stack:
Programming Languages and Libraries:
Python
NumPy, Pandas, Scikit-learn: Here’s a tutorial on basic operations.
Distributed Computing:
- Apache Spark: Parallel processing framework.
Version Control Systems:
- Git
Data Engineering Skills
- SQL
Continuous Integration and Deployment: I learned this on the job
GitHub Actions
Spinnaker
Jenkins
DevOps:
- Docker: This video covers the basics.
Building ML pipelines
Key Phases of an ML Pipeline
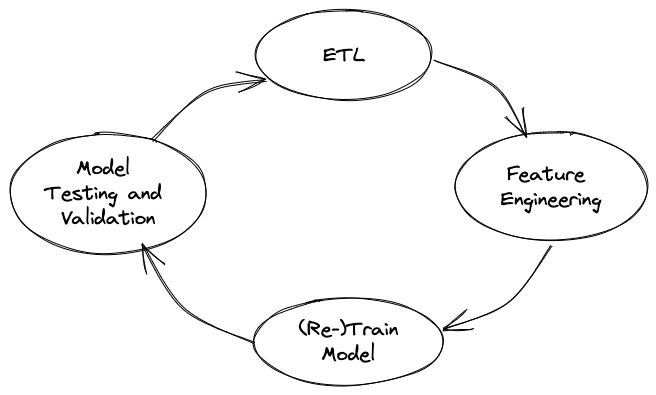
ETL:
Extract data from various sources like:
Data lake (unstructured data)
Data warehouse (structured data)
Hive table
s3 (in the form of parquet/JSON files)
Transform the data by aggregating, joining, and filtering the extracted data.
Load: Store data for downstream processing.
Overall, this step requires data engineering skills which necessitates a firm grasp of SQL concepts.
Feature Engineering:
With FE, the goal is to find the most relevant features that can help the model learn the underlying patterns and relationships in the data.
This step involves handling operations like missing data, encoding categorical variables, scaling numeric data, and creating new features from existing ones.
The output is typically stored in a Feature store.
Training:
The data scientist selects a machine learning model best suited for the use case.
This model is then trained on the preprocessed data using an appropriate algorithm, to minimize the error or loss function.
Once the model is trained, the hyperparameters are adjusted to optimize its performance on a validation dataset.
Testing and Validation
- The model can be scored on a test dataset to asses if the prediction is in-line with business goals.
Automated Workflow
Once the MVP of the ML pipeline is developed, we can streamline the entire pipeline via an automated workflow.
Orchestration tool
Apache Airflow is a popular open-source orchestration tool for automating and managing pipelines.
With Airflow, you can set up alerts to receive notifications when certain tasks fail or when a workflow completes successfully.
You can also configure the number of retries and timeout for each task.
At the heart of Airflow is the concept of a DAG. A Directed acyclic graph is an entity that defines the relationship and dependency between tasks.
Below is an example of a DAG. An essential characteristic of DAG is that the downstream task is not executed until its precursor task is successful.

Each step can be implemented in Python, to perform a specific action, e.g., a bash command, or an entire Training step.
Here’s a short youtube video that will get you started, I encourage you to try to code a DAG.
Underlying Infrastructure
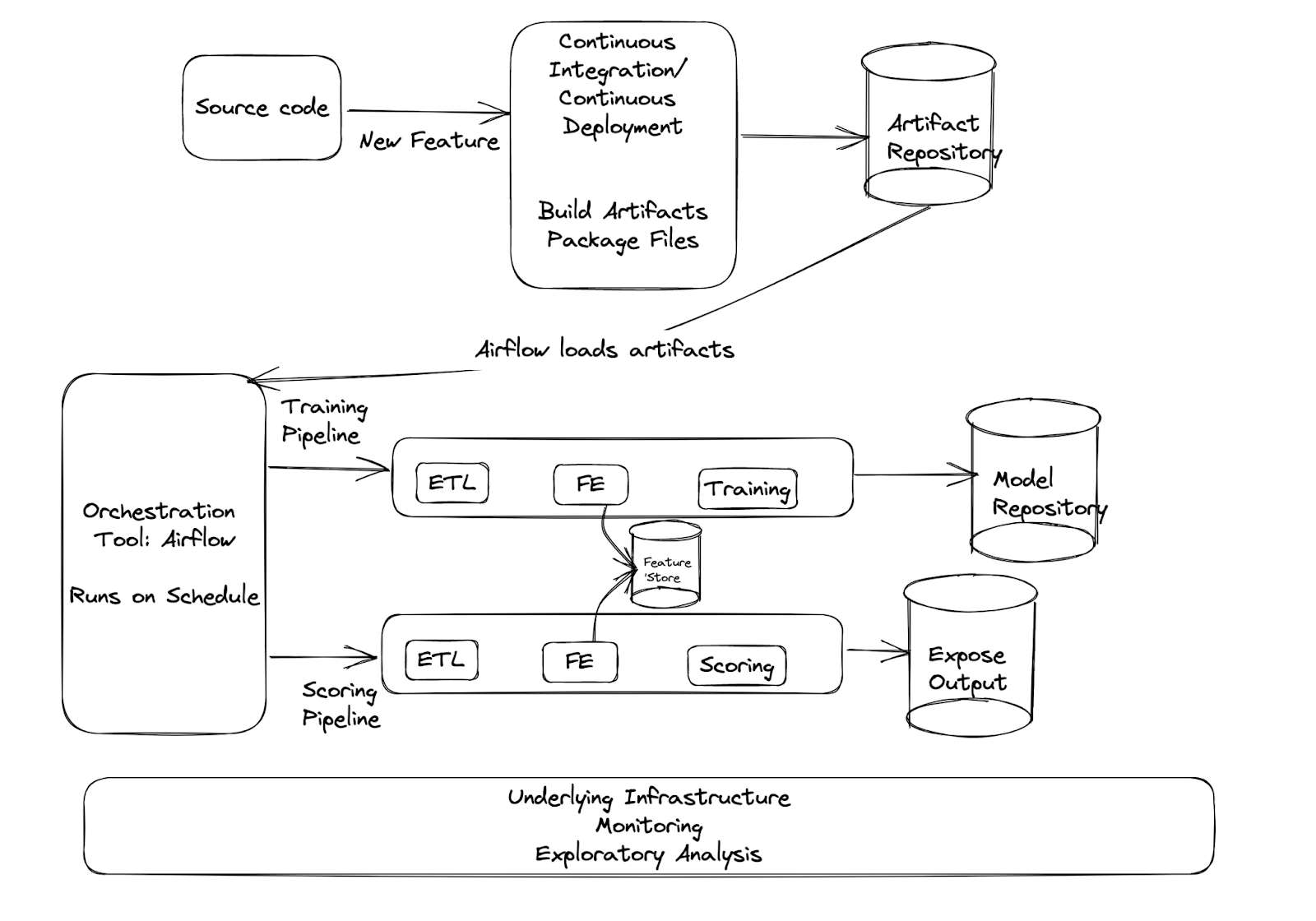
To get a better grasp of the underlying infrastructure of a machine learning pipeline, let’s discuss the latter half of the workday.
To deploy a new feature, you first raise a PR (don’t forget unit tests) and request a code review.
Once you merge this new feature, a pre-setup CI/CD action creates artifacts such as zip, wheel, or Docker files. You set this latest version to be picked up by the Airflow DAG.
Let's take the example of the scoring batch pipeline to explain further steps.
The Airflow scoring DAG kicks off at a pre-set time. This DAG consists of multiple steps such as ETL, FE, and Scoring, each of which is pre-configured to launch on a Spark cluster. Everything runs smoothly in the background.
You suddenly get an alert on Slack mentioning that the ETL step failed. You dig into the Splunk logs and find that the schema has changed for one of the input tables. You reach out to the team responsible for maintaining the hive table and get information on what has changed. Luckily, you are able to fix your code and resume the rest of the pipeline.
Not too long after, you get another alert from Datadog, mentioning that the training pipeline hasn’t been completed by the expected time. You check the Airflow DAG and notice that one of the steps was restarted twice (because of infrastructure issues), but the rest of the pipeline has been running normally and should be completed soon. These alerts are especially essential for time-sensitive output.
Here’s a diagram that explains the infrastructure:
A note about Batch versus Stream Pipeline
Batch pipelines run at predetermined intervals, such as daily or weekly, and are designed for high throughput with less frequent updates.
On the other hand, stream pipelines are meant for live predictions and require low latency.
Traditionally, companies would have separate pipelines for batch and stream processing, which could lead to bugs and inconsistencies.
However, having a feature store that both pipelines can read from can help to overcome this issue.
Conclusion:
Another common question I get is about the future of the MLE role, especially with the advent of AutoML and Generative AI. However, it's important to remember that sensitive applications like pricing optimization still require human intervention and oversight.
Ultimately, what matters most is how much you contribute to driving business value. So, don't let skepticism hold you back from pursuing a career as an MLE and continuing to hone your skills. As long as you remain focused on creating value, your role will remain relevant and impactful.

References:
Highly Recommended Book: Designing ML Systems
Example of unifying Stream and Batch pipelines at Linkedin: https://engineering.linkedin.com/blog/2023/unified-streaming-and-batch-pipelines-at-linkedin--reducing-proc
https://towardsdatascience.com/the-complete-guide-to-the-modern-ai-stack-9fe3143d58ff
ETL pipelines in detail: https://towardsdatascience.com/etl-skills-you-will-need-for-data-science-project-ebc67f7c9277