Feature Engineering for Beginners
Feature Engineering is the process of preparing features (attributes/ characteristics) of the data, for your training model.
Usually, the ETL (Extract, Transform, Load) step is expected to forward tidy data. But sometimes even the tidy data might need some more processing to be ready for the training step.
Before we step into the individual techniques, remember that it is always a good idea to test which technique or sub-technique gives the better result. Also, always store the results of your experimentation.

Let us go through the relevant techniques one-by-one.
1. One hot encoding

Image: Splitting of Categorical Variables
Why exactly is this need step needed? Let's take a scenario where we have a certain column that represents the name of a country. How do you think a model would decipher it? One way the model can process it is via ASCII value. But this would mean some countries would rank higher than the others, which is unwanted.
Moreover, most of the machine learning algorithms work with numerical data (with the exception of decision-based learning algorithms e.g., decision trees)
Another way to solve this problem is via Target Encoding. The advantage of target encoding is that you obtain only one extra column at the end. Refer - Link
2. Feature Hasher
In the worst case, the country column can give rise to 198 values. But what if the unique values in the categorical column run into thousands or millions?
Feature Hashing is one way we can overcome this. As the name suggests, the Hash function maps 'n' features into the desired number of features.
One point to keep in mind before implementing the hash function is the Collision factor i.e., how many input values might be represented by the same hash value.
The trade-off between the Collision factor and the number of features obtained from categorical variables has to be decided by the team.

Image: Feature Hasher
3. Dimensionality reduction
There could be a scenario wherein the incoming data contains too many features. For a small pipeline, 1000 features might increase the computation time of every step, when compared to say, 10 features. In such cases, we can select the most important features using Dimensionality reduction algorithms such as PCA (Principal Component Analysis).

Image: Principal Component Analysis
4. Feature derivation
Consider predicting a stock price model with only the current date and previous day prices. This scenario is an exaggeration, but, what I mean is, we need to be able to collect/synthesize enough features to obtain a good predictive model. Feature derivation is the opposite end of dimensionality reduction.
On a simpler end, you can calculate the mean/ variance of several rows to get a new feature.
On the computationally expensive end, neural networks can be used to derive several features based on simple features present in the data.
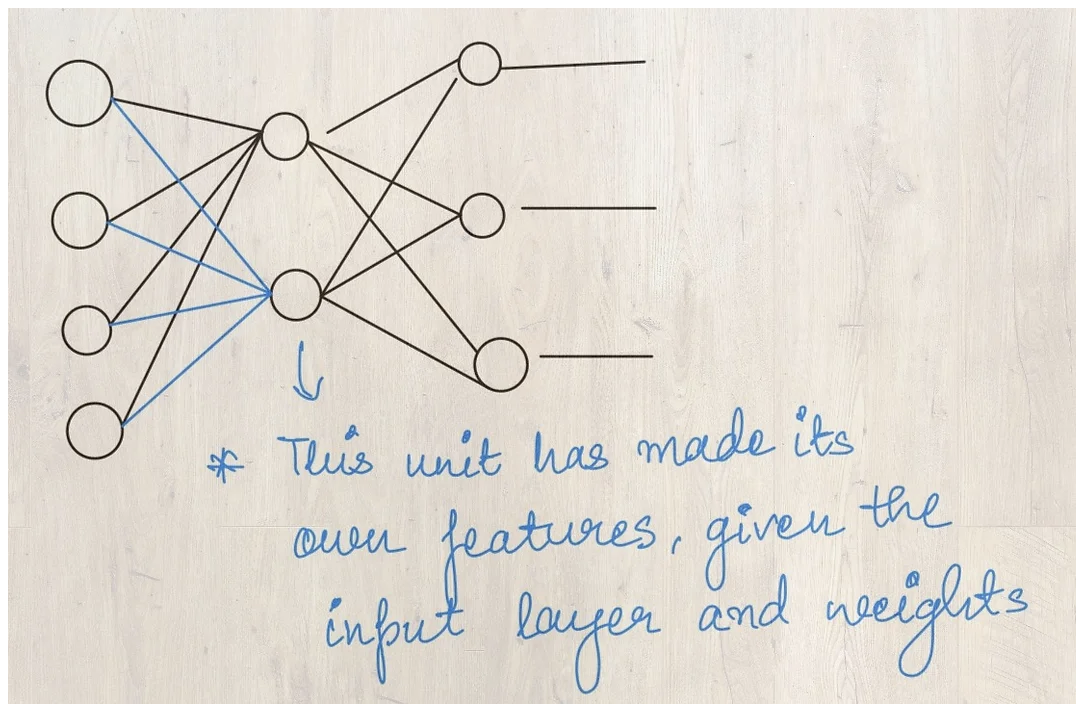
Image: Deriving new features from existing features
Another way to achieve this is via Feature Splitting, wherein you split the combined info into separate features. One common and well-used example is splitting the date variable to derive year, month, day.

Image: Feature Splitting - DATE
5. Feature Scaling
Feature Scaling is the process of bringing the data to the same scale. Why do we need this?
Say we have two columns in the Sales data of smartphones, Price, and the number of units purchased. It could be the case that the Price runs in thousands, while the units remain in single digits. We do not want to end up over-prioritizing and giving extra weight to the Price feature.
There are several ways to achieve this. Let's go over two of the most famous techniques:
Standardization is a scaling technique where the values are centered around the mean with a unit standard deviation.
Normalization is a scaling technique in which values are shifted and rescaled so that they end up ranging between 0 and 1. It is also known as Min-Max scaling.
6. Missing Values - Imputation

If you are working with data, you will spend a considerable amount of time working on the Missing data.
Usually, if 70-80% of the data is missing for a feature, it is dropped. You can adjust the threshold accordingly.
You can also replace the empty cells with the mean/median, or just initialize with a zero value.
7. Miscellaneous
Some additional steps in FE could be:
Dropping outlier features
Taking care of Data leaks
Confirming the Data quality
In case you want to try a hands-on lab for the above concepts, you can refer to this link from Kaggle - Link
That's it for today, thanks for reading!
References:
- Machine Learning Engineering - Andriy Burkov